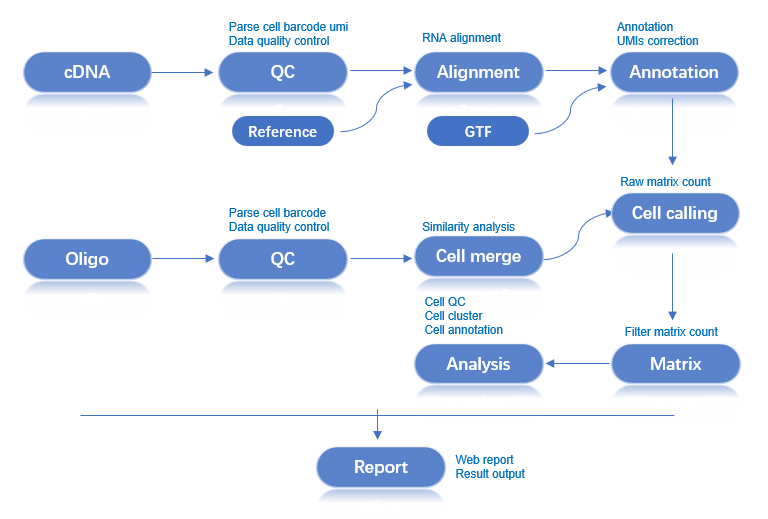
本文档旨在提供一份完整的指南,详细介绍如何使用 dnbc4tools 对单细胞 RNA 测序数据进行分析。
工作流程:原始数据 → 质量控制 → 比对 → 细胞识别 → 表达矩阵 → 分析报告
分析需要两种类型的 FASTQ 文件:
| 文件类型 | 说明 |
|---|---|
| cDNA 文库 | 包含 Cell Barcode、UMI 和转录组信息的测序数据。 |
| Oligo 文库 | 包含大小磁珠的 Cell Barcode 信息及小磁珠的 UMI 信息。 |
| 文件类型 | 格式 | 说明 |
|---|---|---|
| 基因组文件 | FASTA | 包含特定物种的完整基因组序列(通常是主装配版本),涵盖染色体、线粒体及其他遗传信息。该文件是基因组比对和分析的基础。 |
| 注释文件 | GTF | 详细描述基因组中的基因、转录本、外显子等功能区域。此文件明确了基因的位置、类型及相关属性。 |
GTF 文件要求:
从 ENSEMBL 和 UCSC 等网站下载的 GTF 文件通常包含多种类型的基因。根据您的研究兴趣选择特定的基因类型进行分析,可以有效减少基因注释的重叠,从而提高比对的唯一性。与多个基因非唯一比对的 reads 会被过滤。
我们提供以下三种 GTF 文件处理功能:
| 功能 | 说明 |
|---|---|
| 基因类型统计 | 统计 GTF 文件中各基因类型的数量。 |
| GTF 文件校正 | 填补缺失信息,确保 GTF 文件符合分析要求。 |
| 基因类型过滤 | 根据研究需要筛选特定基因类型。 |
# 统计基因类型数量
$dnbc4tools tools mkgtf \
--action stat \
--ingtf genes.gtf \
--output gtfstat.txt \
--type gene_biotype
输出示例:
$cat gtf_type.txt
Type Count
protein_coding 20006
lncRNA 17755
processed_pseudogene 10159
unprocessed_pseudogene 2605
misc_RNA 2221
snRNA 1910
miRNA 1879
TEC 1056
transcribed_unprocessed_pseudogene 950
snoRNA 943
transcribed_processed_pseudogene 503
rRNA_pseudogene 497
IG_V_pseudogene 187
transcribed_unitary_pseudogene 146
IG_V_gene 145
......
当 GTF 文件内容不完整时,主分析流程可能会因无法完全注释而中断。此功能能够自动填补基因(gene)与转录本(transcript)条目中的缺失信息,确保流程顺利进行。
# 校正GTF文件
$dnbc4tools tools mkgtf \
--action check \
--ingtf genes.gtf \
--output corrected.gtf
软件会根据 gene_id 和 gene_name 以及 transcript_id 和 transcript_name 互相填补,并提示可能存在多个基因信息的位置。
# 基因类型过滤
$dnbc4tools tools mkgtf \
--ingtf genes.gtf \
--output genes.filter.gtf \
--type gene_biotype
默认包含的基因类型:
protein_coding
lncRNA/lincRNA
antisense
IG_V_gene
IG_LV_gene
IG_D_gene
IG_J_gene
IG_C_gene
IG_V_pseudogene
IG_J_pseudogene
IG_C_pseudogene
TR_V_gene
TR_D_gene
TR_J_gene
TR_C_gene
您也可以使用 include 参数自定义需要保留的基因类型:
# 自定义基因类型过滤
$dnbc4tools tools mkgtf \
--ingtf genes.gtf \
--output genes.filter.gtf \
--type gene_biotype \
--include protein_coding,lncRNA,lincRNA,\
antisense,IG_V_gene,IG_LV_gene,IG_J_gene,\
IG_C_gene,IG_V_pseudogene,IG_J_pseudogene,\
IG_C_pseudogene,TR_V_gene,TR_D_gene,TR_J_gene,TR_C_gene
在执行 dnbc4tools rna run 分析前,必须先构建参考数据库。此步骤利用注释文件(GTF)和参考基因组(FASTA)创建索引,用于后续测序 reads 的比对和注释。
# 构建参考数据库
$dnbc4tools rna mkref \
--fasta genome.fa \
--ingtf genes.gtf \
--species Homo_sapiens \
--threads 10
输出结果:
成功运行后,将在指定位置创建参考数据库目录,包含以下文件结构:
/opt/database/Homo_sapiens
├── fasta
│ ├── genome.fa
│ └── genome.fa.fai
├── genes
│ └── genes.gtf
├── ref.json
└── star
├── chrLength.txt
├── chrNameLength.txt
├── chrName.txt
├── chrStart.txt
├── exonGeTrInfo.tab
├── exonInfo.tab
├── geneInfo.tab
├── Genome
├── genomeParameters.txt
├── mtgene.list
├── SA
├── SAindex
├── sjdbInfo.txt
├── sjdbList.fromGTF.out.tab
├── sjdbList.out.tab
└── transcriptInfo.tab
其中 ref.json 文件记录了数据库的主要信息。
{
"chrmt": "chrM",
"genome": "/opt/database/Homo_sapiens/fasta/genome.fa",
"genomeDir": "/opt/database/Homo_sapiens/star",
"gtf": "/opt/database/Homo_sapiens/genes/genes.gtf",
"input_fasta_files": [
"genome.fa"
],
"input_gtf_files": [
"genes.filter.gtf"
],
"mtgenes": "/opt/database/Homo_sapiens/star/mtgene.list",
"species": "Homo_sapiens",
"version": "dnbc4tools 3.0beta"
}
运行时将打印如下信息:
Creating new reference folder at /opt/database/Homo_sapiens
...done
Writing genome FASTA file into reference folder...
...done
Indexing genome FASTA file...
...done
Writing genes GTF file into reference folder...
...done
Generating STAR genome index...
...done.
Writing Reference JSON file into reference folder...
...done
Analysis Complete
为简化多样本分析流程,您可以使用配置文件批量生成针对每个样本的 shell 脚本。
$dnbc4tools rna multi \
--list sample.tsv \
--genomeDir /opt/database/Homo_sapiens \
--threads 30
其中 sample.tsv 文件使用制表符 (\t) 分隔,包含三列:
| 列 | 内容 |
|---|---|
| 1 | 样本名称 |
| 2 | cDNA 文库测序数据 |
| 3 | Oligo 文库测序数据 |
sample1 /data/cDNA1_R1.fq.gz;/data/cDNA1_R2.fq.gz /data/oligo1_R1.fq.gz,/data/oligo4_R1.fq.gz;/data/oligo1_R2.fq.gz,/data/oligo4_R2.fq.gz
sample2 /data/cDNA2_R1.fq.gz;/data/cDNA2_R2.fq.gz /data/oligo2_R1.fq.gz;/data/oligo2_R2.fq.gz
sample3 /data/cDNA3_R1.fq.gz;/data/cDNA3_R2.fq.gz /data/oligo3_R1.fq.gz;/data/oligo3_R2.fq.gz
运行完成后,将为每个样本生成一个 shell 脚本:
sample1.sh
sample2.sh
sample3.sh
sample1.sh 文件内容示例:
$cat sample1.sh
/opt/software/dnbc4tools3.0beta/dnbc4tools rna run --name sample1 --cDNAfastq1 /data/cDNA1_R1.fq.gz --cDNAfastq2 /data/cDNA1_R2.fq.gz --oligofastq1 /data/oligo1_R1.fq.gz,/data/oligo4_R1.fq.gz --oligofastq2 /data/oligo1_R2.fq.gz,/data/oligo4_R2.fq.gz --genomeDir /database/scRNA/Mus_musculus/mm10 --threads 30
随后,您可以执行这些脚本以进行主流程分析。
RNA 主分析流程处理单个样本的 cDNA 和 Oligo 文库测序数据。该流程的核心步骤包括:
为单个样本生成表达矩阵的示例脚本:
$dnbc4tools rna run \
--name sample \
--cDNAfastq1 /data/sample_cDNA_R1.fastq.gz \
--cDNAfastq2 /data/sample_cDNA_R2.fastq.gz \
--oligofastq1 /data/sample_oligo1_1.fq.gz,/data/sample_oligo2_1.fq.gz \
--oligofastq2 /data/sample_oligo1_2.fq.gz,/data/sample_oligo2_2.fq.gz \
--genomeDir /opt/database/Homo_sapiens \
--threads 30
在对试剂版本和暗反应自动检测后,软件开始运行分析,以下是一个示例:
2025-06-04 16:29:35 Performing RNA data processing
Chemistry(darkreaction) determined in oligoR1: darkreaction
Chemistry(darkreaction) determined in oligoR2: darkreaction
Chemistry(darkreaction) determined in cDNAR1: darkreaction
2025-06-04 16:29:37 Processing oligo library filtering...
...done
2025-06-04 16:59:39 Processing cDNA library filtering...
...done
2025-06-04 17:50:10 Processing alignment and counting...
...done
2025-06-05 01:20:56 Calculating bead similarity, merging beads within the same droplet...
...done
2025-06-05 01:22:17 Generating raw gene expression matrix...
...done
2025-06-05 01:31:38 Generating cell-filtered gene expression matrix...
...done
2025-06-05 01:33:07 Calculating sequencing saturation metrics...
...done
2025-06-05 01:34:23 Generating position-sorted BAM file...
...done
2025-06-05 02:23:17 Performing dimensionality reduction and clustering analysis...
...done
2025-06-05 02:24:57 Generating analysis report and summary statistics...
...done
Analysis Finished
Elapsed Time: 9:56:09
当出现 Analysis Finished 消息时,表示分析已成功完成。
分析完成后,将生成 outs(结果输出)和 logs(日志)目录。outs 目录结构如下:
.
├── analysis/
│ ├── cluster.csv
│ ├── marker.csv
│ └── QC_Cluster.h5ad
├── anno_decon_sorted.bam
├── anno_decon_sorted.bam.bai
├── filter_feature.h5ad
├── filter_matrix/
│ ├── barcodes.tsv.gz
│ ├── features.tsv.gz
│ └── matrix.mtx.gz
├── metrics_summary.xls
├── raw_matrix/
│ ├── barcodes.tsv.gz
│ ├── features.tsv.gz
│ └── matrix.mtx.gz
├── *_scRNA_report.html
└── singlecell.csv
相关文档:
内容待补充