单细胞RNA分析完成后,会在指定的输出目录中生成标准化的文件和子目录结构,专门用于基因表达谱分析和细胞类型鉴定。本文档详细说明了每个输出文件的内容、格式和用途,帮助用户充分理解和高效利用单细胞RNA分析结果。
💡 提示: 所有输出文件均采用标准格式,兼容主流单细胞分析工具(如Scanpy、Seurat等),遵循国际通用的数据格式规范。
.
├── analysis/ # 下游分析结果目录
│ ├── cluster.csv # 细胞聚类结果文件
│ ├── marker.csv # 差异表达基因标记文件
│ └── QC_Cluster.h5ad # 质控和聚类后的AnnData对象
├── anno_decon_sorted.bam # 比对注释并排序的BAM文件
├── anno_decon_sorted.bam.bai # BAM索引文件
├── filter_feature.h5ad # 过滤后的特征矩阵(AnnData格式)
├── filter_matrix/ # 过滤后的基因表达矩阵目录
│ ├── barcodes.tsv.gz # 细胞条形码文件
│ ├── features.tsv.gz # 基因/特征信息文件
│ └── matrix.mtx.gz # 稀疏矩阵文件(Market Matrix格式)
├── metrics_summary.xls # 分析指标汇总表
├── raw_matrix/ # 原始基因表达矩阵目录
│ ├── barcodes.tsv.gz # 原始细胞条形码文件
│ ├── features.tsv.gz # 原始基因/特征信息文件
│ └── matrix.mtx.gz # 原始稀疏矩阵文件
├── singlecell.csv # 单细胞metadata信息表
└── *_scRNA_report.html # HTML格式的分析报告
🎯 核心内容: 原始测序数据比对到参考基因组的结果文件,包含完整的比对信息和细胞条形码标记
这是包含所有原始数据的 scRNA-seq 比对结果文件。
核心用途:
内容与格式:
.bai 文件),便于快速随机访问。关键TAG字段说明:
🧬 细胞和分子标识标签:
| 标签 | 类型 | 描述 | 生物学意义 |
|---|---|---|---|
CB |
String | 细胞条形码合并后的细胞ID | 用于将reads归属到特定细胞,是经过纠错和合并的最终细胞ID |
CC |
String | 经过错误校正细胞条形码序列 | 纠错后的细胞条形码,是生成CB标签的中间步骤 |
CR |
String | 原始测序细胞条形码 | 保留原始测序信息,用于质量评估和错误追溯 |
CY |
String | 细胞条形码质量分数 | Phred质量分数,评估条形码测序的可靠性 |
UB |
String | 错误校正后的UMI序列 | 用于分子去重,识别PCR重复和原始mRNA分子 |
UR |
String | 原始测序UMI序列 | 保留原始UMI信息,用于质量评估和算法优化 |
UY |
String | UMI质量分数 | Phred质量分数,评估UMI测序的准确性 |
🧬 基因注释和功能标签:
| 标签 | 类型 | 描述 | 功能用途 |
|---|---|---|---|
GX |
String | Ensembl ID | 基因表达定量的主要ID |
GN |
String | 基因名称 | 便于生物学解释,支持基因功能注释 |
TX |
String | 转录本ID | 用于转录本水平的表达分析和可变剪接研究 |
AN |
String | 反义转录本标记 | 识别反义RNA,评估文库方向性和非编码RNA表达 |
RE |
String | 基因组区域类型 | 区分外显子(E)、内含子(N)、基因间区(I),用于转录组特征分析 |
anno_decon_sorted.bam 文件的索引。
索引文件由 samtools index 命令生成。为了兼容不同大小的基因组,流程会自动选择合适的索引格式(BAI 或 CSI)。
| 格式类型 | 使用说明 |
|---|---|
| BAI 格式 | 默认生成的索引格式,兼容性最佳,适用于大多数分析工具和基因组。 |
| CSI 格式 | 当BAM文件包含长度超过 512 Mbp (2^29-1 bp) 的染色体时自动生成,以支持超大基因组。 |
🎯 核心内容: 单细胞基因表达计数矩阵,分为原始数据和质控过滤后数据,采用标准稀疏矩阵或AnnData格式
filter_matrix/)包含经过高质量细胞过滤后的基因表达计数矩阵,是进行下游定量分析的核心数据。
核心用途:
内容与格式:
| 文件名 | 内容描述 |
|---|---|
barcodes.tsv.gz |
细胞ID列表,标识通过质控筛选的高质量细胞。每行包含一个细胞ID信息,对应矩阵的列索引 |
features.tsv.gz |
基因/特征信息文件,包含基因ID、名称和类型。每行包含三列信息,对应矩阵的行索引 |
matrix.mtx.gz |
基因表达计数矩阵,采用 Market Matrix 格式。包含矩阵维度信息和非零元素的行、列索引及数值 |
格式优势:
.mtx)仅存储非零元素,极大节省了存储空间。raw_matrix/)包含所有检测到的细胞条形码(未经过滤)的原始基因表达计数矩阵。
核心用途:
内容与格式:
filter_matrix/ 目录完全相同。经过细胞鉴定和过滤后的特征矩阵,采用 AnnData (.h5ad) 格式存储,是 filter_matrix/ 目录内容的替代和补充。
scanpy 等Python单细胞分析库的标准输入格式,无缝衔接下游分析。analysis/) 🎯 核心内容: 下游生物信息学分析结果,包括细胞聚类、差异基因和质控后数据
细胞聚类分析结果文件,采用 CSV 格式。包含每个细胞的ID、所属聚类、降维坐标以及关键质控指标。
Barcode: 细胞IDCluster: 该细胞所属的聚类编号UMAP_1, UMAP_2: UMAP降维的二维坐标nGene, nUMI: 每个细胞检测到的基因数和UMI数各聚类的差异表达基因(标记基因)列表,采用 CSV 格式。记录了每个基因在特定聚类中的表达显著性、表达量变化等信息。
cluster: 基因作为标记基因的聚类编号gene: 基因名称avg_log2FC: 平均对数倍数变化p_val_adj: 调整后的p值,评估统计显著性pct.1, pct.2: 该基因在目标聚类和其他聚类中的表达细胞比例经过完整质控、降维和聚类分析的单细胞数据对象,采用 AnnData (.h5ad) 格式。它整合了上游的表达矩阵和下游的分析结果。
scanpy中加载,进行深入探索性分析或可视化。filter_feature.h5ad 的基础上,增加了以下信息:
obs: 包含聚类结果 (cluster) 等细胞元数据。obsm: 包含降维坐标 (X_umap)。uns: 包含标记基因 (marker_genes) 等非结构化结果。🎯 核心内容: 实验质量评估和统计指标汇总,提供完整的数据质量控制信息
采用 Excel 格式的关键分析指标汇总表,提供了对实验整体质量的全面评估。
核心用途:
内容与格式:
| 指标类别 | 包含内容 |
|---|---|
| 基本统计 | 总 reads数、有效条形码比例、UMI质量、Q30碱基质量等基础测序指标 |
| 细胞识别 | 估计细胞数量、每细胞中位基因/UMI数、测序饱和度等细胞调用结果 |
| 比对指标 | 基因组比对率、转录组比对率、外显子/内含子比例等比对统计 |
采用 CSV 格式的单细胞级别质量控制信息表,记录了每个细胞条形码的详细统计数据。
核心用途:
内容与格式:
采用 HTML 网页格式的交互式综合分析报告。
核心用途:
内容与格式:
技术规范: 输出文件采用的标准格式详细说明
.mtx.gz) Market Exchange Format (MEX) 是单细胞分析中用于存储稀疏计数矩阵的标准格式,具有空间高效和高度兼容的优点。
核心优势:
文件组成:
| 文件名 | 描述 |
|---|---|
matrix.mtx.gz |
压缩的稀疏矩阵文件。文件头包含矩阵维度,后续每行记录一个非零元素的位置(行/列索引)和数值。 |
barcodes.tsv.gz |
压缩的细胞条形码文件。每行是一个细胞ID,行号对应矩阵的列。格式例如`CELL1_N2`,其中`CELL1`为细胞ID,`N2`为由两个条形码组成。 |
features.tsv.gz |
压缩的特征(基因)文件。每行包含基因ID、基因名称等信息,行号对应矩阵的行。 |
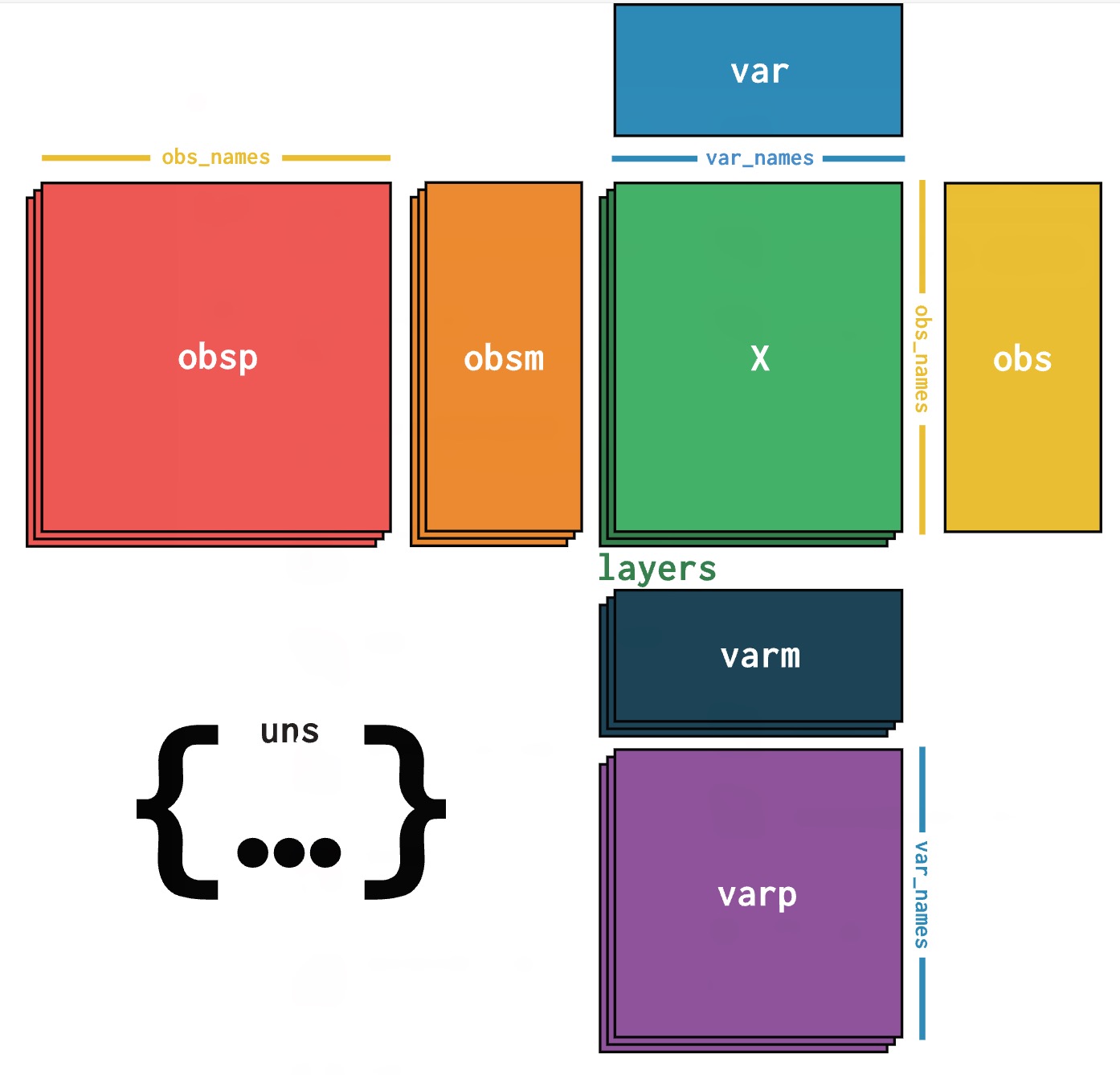
.h5ad) 格式概述: AnnData ("Annotated Data") 是专为矩阵型数据设计的数据结构,特别适用于单细胞RNA测序数据分析。基于HDF5格式,提供高效的数据存储和访问能力。
| 📁 组件 | 🎯 功能 | 📏 维度 |
|---|---|---|
| X | 主表达矩阵 | n_cells × n_genes |
| obs | 细胞元数据 | n_cells × n_obs_features |
| var | 基因元数据 | n_genes × n_var_features |
| obsm | 细胞多维数据 | n_cells × n_components |
| varm | 基因多维数据 | n_genes × n_components |
| layers | 多层数据 | n_cells × n_genes |
| uns | 非结构化数据 | 任意对象 |
🎯 概述: HTML网页报告提供了单细胞RNA测序分析结果的全面可视化展示和详细解读,包含关键性能指标的评估,帮助用户快速了解实验质量和分析结果
HTML网页报告是单细胞RNA测序分析的综合展示平台,整合了从数据质量控制到下游生物学分析的完整结果。该报告采用交互式可视化设计,帮助用户快速评估实验质量、理解分析结果并指导后续研究方向。
💡 使用建议: 建议按照报告展示顺序依次查看各项指标。
⚠️ 质量标准: 各项指标均提供了推荐阈值和质量等级,请结合具体实验目标进行综合评估。
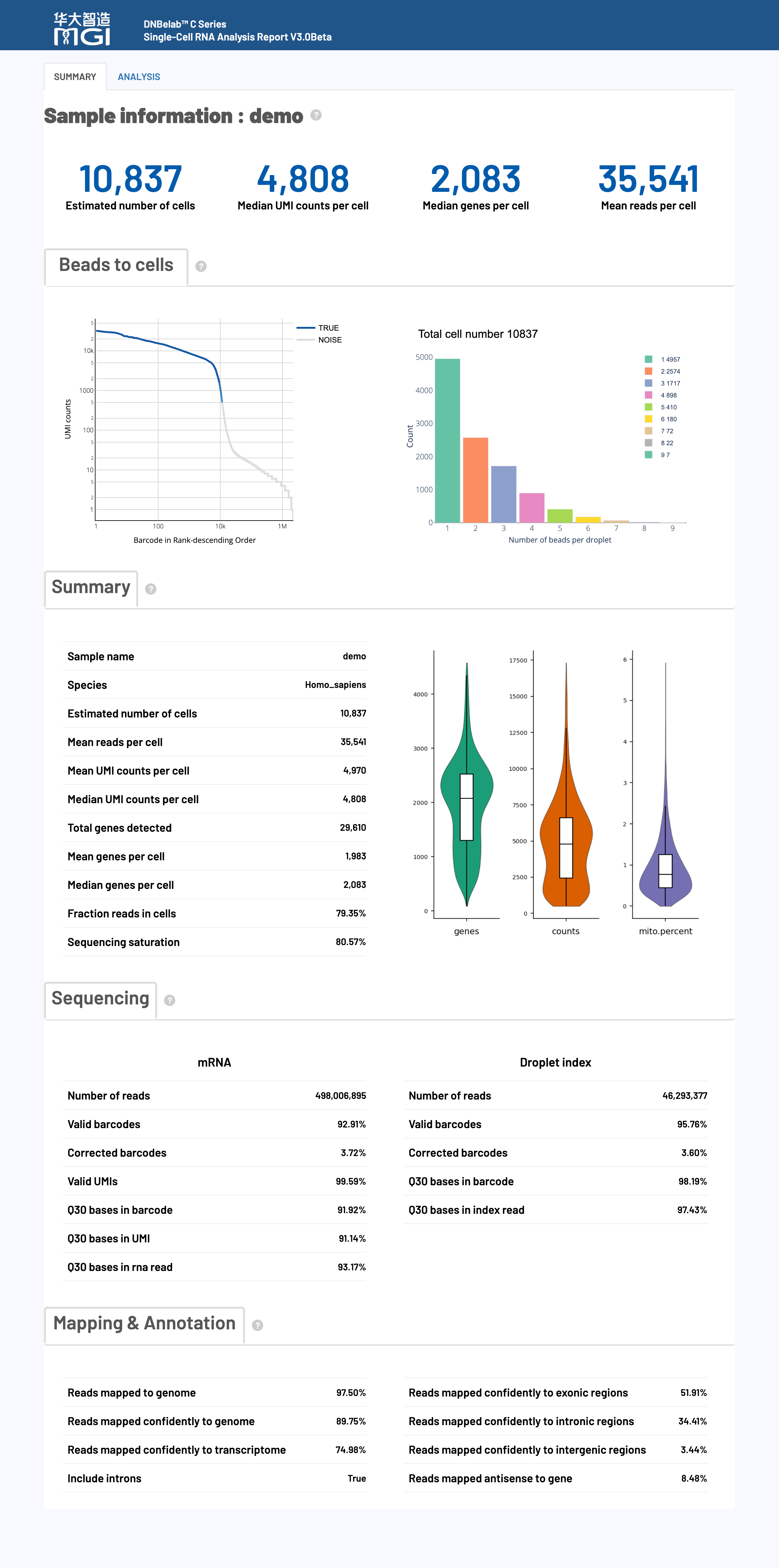
🎯 核心功能: 细胞识别、质量评估和基因表达统计,提供实验整体效果的关键指标
📊 质量控制标准:
注意: 以下标准仅供参考,实际质量评估应考虑组织类型、细胞状态和实验目标等多种因素。不同样本间存在显著差异,建议结合具体实验背景进行判断。
| 指标名称 | 推荐值 | 可接受 | 需优化 |
|---|---|---|---|
| Mean reads per cell | ≥ 30,000 | 15,000–30,000 | < 15,000 |
| Median genes per cell | ≥ 1,000 | 500–1,000 | < 500 |
| Fraction reads in cells | ≥ 60% | 30–60% | < 30% |
| Sequencing saturation | ≥ 40% | 20–40% | < 20% |
🔍 详细指标解释:
| 指标名称 | 详细解释与技术要求 |
|---|---|
|
Estimated number of cells 估计细胞数量 |
|
|
Species 物种信息 |
|
|
Mean reads per cell 每细胞平均Reads数 |
|
|
Median/Mean UMI per cell 细胞中位/平均UMI数 |
|
|
Median/Mean genes per cell 细胞中位/平均基因数 |
|
|
Total genes detected 检测到的总基因数 |
|
|
Fraction reads in cells 细胞内Reads比例 |
|
|
Sequencing saturation 测序饱和度 |
|
🎯 核心功能: 测序数据的基础质量评估,包括条形码识别率、UMI质量和测序准确性
📊 质量控制标准:
注意: 以下标准仅供参考,实际质量评估应考虑组织类型、细胞状态和实验目标等多种因素。不同样本间存在显著差异,建议结合具体实验背景进行判断。
| 指标类别 | 推荐值 | 可接受 | 需优化 |
|---|---|---|---|
| Valid barcodes | ≥ 80% | 70–80% | < 70% |
| Valid UMIs | ≥ 80% | 70–80% | < 70% |
| Q30 Base Quality | ≥ 85% | 75–85% | < 75% |
🔍 详细指标解释:
| 指标名称 | 详细解释与技术要求 |
|---|---|
|
Number of reads 测序读段总数 |
|
|
Valid barcodes 有效条形码比例 |
|
|
Valid UMIs 有效UMI比例 |
|
|
Q30 bases in barcode/UMI/read Q30碱基比例 |
|
注: 以上所有比例的计算均以原始测序读段(Number of Reads)为准,确保了各项指标之间的可比性和一致性。
🎯 核心功能: 评估reads与参考基因组的比对质量,包括比对率、特异性和基因组区域分布
📊 质量控制标准:
注意: 以下标准仅供参考,实际质量评估应考虑组织类型、细胞状态和实验目标等多种因素。不同样本间存在显著差异,建议结合具体实验背景进行判断。
| 指标名称 | 推荐值 | 可接受 | 需优化 |
|---|---|---|---|
| Reads mapped to genome | ≥ 80% | 50–80% | < 50% |
| Reads mapped confidently to transcriptome | ≥ 50% | 30-50% | < 30% |
| Reads mapped antisense to gene | < 10% | 10-30% | > 30% |
🔍 详细指标解释:
| 指标名称 | 详细解释与技术要求 |
|---|---|
|
Reads mapped to genome 基因组比对率 |
|
|
Reads mapped confidently to genome 基因组置信比对率 |
|
|
Reads mapped confidently to transcriptome 转录组置信比对率 |
|
|
Reads mapped confidently to exonic regions 外显子区域比对率 |
|
|
Reads mapped confidently to intronic regions 内含子区域比对率 |
|
|
Reads mapped confidently to intergenic regions 基因间区比对率 |
|
|
Reads mapped antisense to gene 反义比对率 |
|
|
Include introns 包含内含子 |
|
注: 以上所有比例的计算均以原始测序读段(Number of Reads)为准,确保了各项指标之间的可比性和一致性。
🎯 核心功能: 提供全面的数据可视化分析,从细胞质量控制到下游生物学分析的完整展示
图表功能:
该图通过将所有细胞按其包含的UMI数进行排序,来区分高质量的真实细胞与背景噪音。
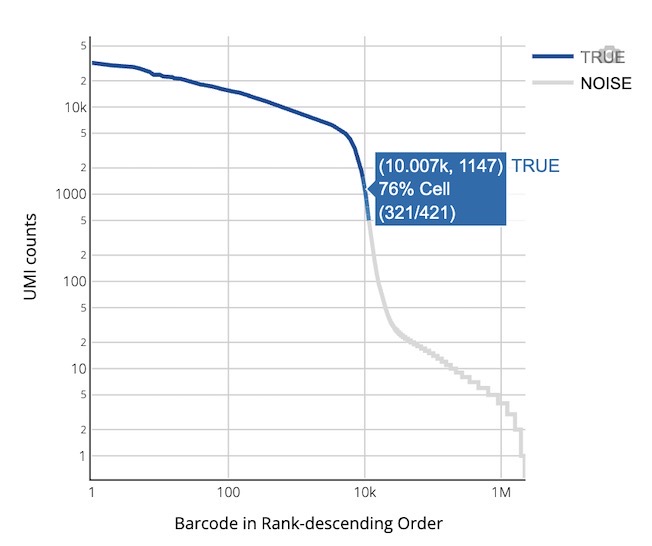
如何解读:
图表功能:
展示在真实细胞液滴中,捕获到的细胞条形码(Beads)的数量分布情况。
如何解读:
图表功能:
通过三个独立的小提琴图,分别展示高质量细胞在 基因数 (nGenes)、UMI数 (nUMI) 和 线粒体基因比例 (percent.mt) 这三个关键质量指标上的分布情况。
如何解读:
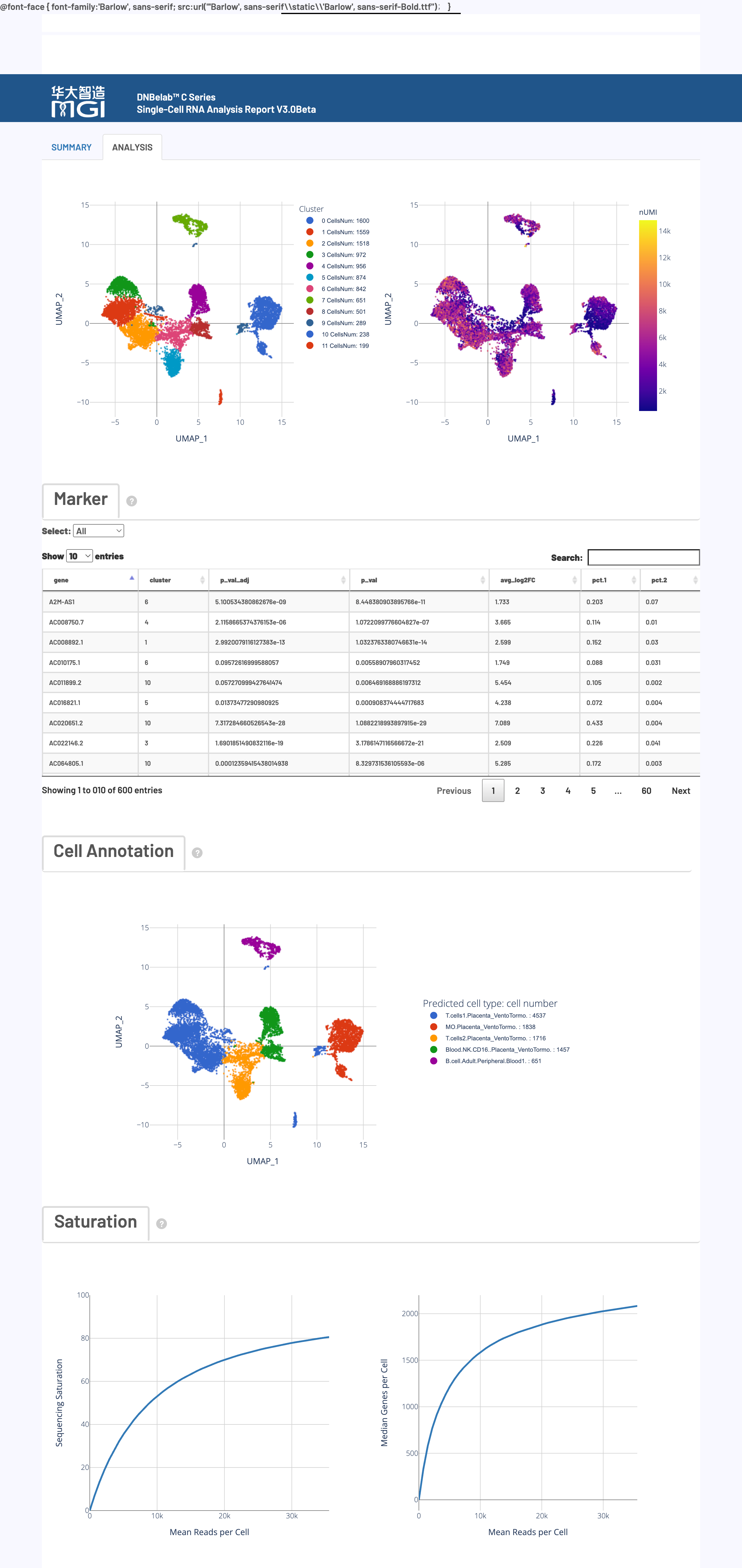
🎯 核心功能: 细胞聚类分析、差异基因识别、细胞类型注释和测序深度评估的综合展示
图表功能:
通过UMAP降维和Louvain聚类算法,将具有相似基因表达模式的细胞在二维空间中聚集在一起,从而识别潜在的细胞亚群。
如何解读:
图表功能:
展示每个细胞聚类的特征性差异表达基因,用于识别和注释不同的细胞类型。
如何解读:
图表功能:
在UMAP图上,使用从参考数据库(如scHCL, scMCA)推断的细胞类型对每个聚类进行标注。
如何解读:
图表功能:
评估测序深度的充分性和数据复杂度,即继续增加测序量能否发现更多新的基因或UMI。
如何解读:
| 文档类型 | 资源链接和描述 |
|---|---|
| 🚀 快速入门 | 快速入门指南 - 第一次分析的完整教程 |
| ⚙️ 参数参考 | 参数参考手册 - 所有可配置参数的详细说明 |
| 🔬 分析流程 | 分析流程说明 - 整个分析流程的技术细节 |
| 🔧 安装配置 | 安装配置指南 - 系统要求、安装步骤和环境配置 |
💡 提示
本文档持续更新中,如发现内容错误或需要补充的信息,欢迎反馈。
📝 文档版本: 3.0 beta | 最后更新: 2025年
🔬 DNBelab C Series HT scRNA Analysis Software
高性能单细胞RNA测序数据分析流程