
单细胞VDJ分析完成后,会在指定的输出目录中生成标准化的文件和子目录结构,专门用于免疫受体库谱分析。本文档详细说明了每个输出文件的内容、格式和用途,帮助用户充分理解和高效利用V(D)J分析结果。
💡 提示: VDJ分析需要基于5'端RNA测序数据,所有输出文件遵循AIRR标准并兼容主流免疫组学分析工具。
⚠️ 前提条件: 需要先完成5'端单细胞RNA测序分析
.
├── airr_annotations.tsv # AIRR标准格式的注释文件
├── all_contig_annotations.csv # 所有组装序列的注释信息
├── all_contig.fasta # 所有组装序列的FASTA文件
├── all_contig.fasta.fai # 所有组装序列的索引文件
├── clonotypes.csv # 克隆型分析结果
├── consensus_annotations.csv # 一致性序列注释信息
├── consensus.fasta # 一致性序列FASTA文件
├── consensus.fasta.fai # 一致性序列索引文件
├── filtered_contig_annotations.csv # 过滤后组装序列的注释信息
├── filtered_contig.fasta # 过滤后的组装序列FASTA文件
├── filtered_contig.fasta.fai # 过滤后组装序列的索引文件
├── metrics_summary.xls # 分析质量指标汇总表
└── *_scVDJ_TR(IG)_report.html # HTML格式的分析报告
🎯 核心内容: V(D)J 重叠群序列组装、精确注释和质量评估结果,涵盖 TCR 和 BCR 重排序列的完整信息
典型 V(D)J 转录本结构示意:
🔍 重要术语解释:
| 组成区域 | 英文缩写 | 生物学功能 |
|---|---|---|
| 非翻译区 | UTR (Untranslated Region) | 调控 mRNA 稳定性和翻译效率,不编码蛋白质 |
| 框架区 | FWR (Framework Region) | 维持免疫球蛋白折叠的保守性结构框架 |
| 互补决定区 | CDR (Complementarity Determining Region) | 直接与抗原接触,决定结合特异性的关键可变区域 |
🧬 技术优势: V(D)J 分析流程可精确识别并提供框架区(FWR)和互补决定区(CDR)的氨基酸与核苷酸序列。所有组装重叠群和克隆型共识序列的 V(D)J 注释信息均以多种标准格式输出。
重叠群序列被认定为 全长序列 须同时满足以下严格条件:
重叠群序列被认定为 生产性序列(具有功能活性)须同时满足以下所有条件:
🔬 不同细胞类型的预期受体配置:
| 细胞类型 | 标准受体配置 | 生物学意义 |
|---|---|---|
| T 细胞 | 1 个生产性 TRA 链 + 1 个生产性 TRB 链 | 正常 TCR α/β 异源二聚体 |
| B 细胞 | 1 个生产性重链 + 1 个生产性轻链(κ 或 λ) | 正常 BCR 重链/轻链配对 |
🤔 低置信度序列标记原则:
⚠️ 重要提示:超出正常配置的额外生产性重叠群通常为异常情况,可能源于:
| 异常类型 | 原因分析 |
|---|---|
| 环境污染 | 游离 mRNA 的非特异性捕获,可能来自外源污染或凋亡细胞释放的核酸 |
| 双细胞事件 | 液滴中包含多个细胞 (doublets),导致无法区分不同细胞的受体信号 |
| 技术伪影 | PCR 扩增或测序过程中的人工序列,包括嵌合体序列或错误的引物结合 |
📉 低置信度序列的判定依据:
包含V(D)J重排的注释序列和共识序列,采用AIRR标准格式。
用途:
内容与格式:
| 字段名 | 详细描述 |
|---|---|
cell_id |
该重排序列所属细胞的唯一标识符,用于关联单细胞数据 |
clone_id |
克隆型编号,标识该重排序列归属的特定克隆群体,用于克隆型分析 |
sequence_id |
重叠群(重排序列)的唯一名称或标识符 |
sequence |
V(D)J 重排的完整核苷酸序列,包含所有可变、多样性和连接区域 |
sequence_aa |
重排区域翻译获得的氨基酸序列,反映功能性蛋白产物 |
productive |
标记该重排是否为生产性(具有生物学功能),需满足框内翻译和无终止密码子等条件 |
rev_comp |
指示序列是否为反向互补序列(默认:false),用于序列方向标记 |
v_call |
识别的 V(可变)基因片段名称 |
v_cigar |
V 基因比对的 CIGAR 字符串,记录比对的详细信息(匹配、插入、删除等) |
d_call |
识别的 D(多样性)基因片段名称(仅适用于重链和 β 链) |
d_cigar |
D 基因比对的 CIGAR 字符串,详细记录多样性区域的比对结果 |
j_call |
识别的 J(连接)基因片段名称,完成 V(D)J 重组的关键元件 |
j_cigar |
J 基因比对的 CIGAR 字符串,记录连接区域的精确比对信息 |
c_call |
识别的 C(恒定)基因片段名称,决定抗体/受体的功能类型 |
c_cigar |
C 基因比对的 CIGAR 字符串,记录恒定区域的比对详情 |
sequence_alignment |
V(D)J 重排区域与参考种系序列的详细比对结果,显示突变和变异 |
germline_alignment |
推断的种系全长序列比对结果,用于体细胞突变分析 |
junction |
V(D)J 重排连接区的核苷酸序列(CDR3 区域),决定抗原结合特异性 |
junction_aa |
重排连接区的氨基酸序列(CDR3 氨基酸),抗原识别的关键结构域 |
junction_length |
CDR3 区域核苷酸序列长度(bp),影响抗原结合能力和特异性 |
junction_aa_length |
CDR3 区域氨基酸序列长度(aa),决定抗原结合环的空间结构 |
v_sequence_start |
V 区域在重排序列中的起始位置(1-based 坐标系统) |
v_sequence_end |
V 区域在重排序列中的结束位置(1-based 坐标系统) |
d_sequence_start |
D 区域在重排序列中的起始位置(1-based 坐标系统) |
d_sequence_end |
D 区域在重排序列中的结束位置(1-based 坐标系统) |
j_sequence_start |
J 区域在重排序列中的起始位置(1-based 坐标系统) |
j_sequence_end |
J 区域在重排序列中的结束位置(1-based 坐标系统) |
c_sequence_start |
C 区域在重排序列中的起始位置(1-based 坐标系统) |
c_sequence_end |
C 区域在重排序列中的结束位置(1-based 坐标系统) |
consensus_count |
支持该重排序列的总 reads 数量,反映测序深度和序列可信度 |
duplicate_count |
支持该重排序列的独特 UMI 分子数量,用于去重和定量分析 |
is_cell |
标记该重排是否来源于真实细胞(TRUE:细胞;FALSE:背景/空滴) |
包含所有重叠群序列(来自细胞和背景条形码)的详细注释信息。
用途:
内容与格式:
| 字段名 | 描述 |
|---|---|
sample |
VDJ文库的样本名称 |
barcode |
该重叠群对应的细胞ID(或条形码) |
is_cell |
布尔值,指示该细胞ID是否被识别为细胞(TRUE为细胞,FALSE为背景) |
contig_id |
该重叠群的唯一标识符 |
high_confidence |
布尔值,指示该重叠群是否被标记为高置信度(不太可能是嵌合序列或其他伪影) |
length |
重叠群序列的核苷酸长度(bp) |
chain |
与该重叠群相关的链类型:TRA、TRB、IGK、IGL或IGH |
v_gene |
得分最高的V基因片段,如TRAV1-1 |
d_gene |
得分最高的D基因片段,如TRBD1 |
j_gene |
得分最高的J基因片段,如TRAJ1-1 |
full_length |
布尔值,指示该重叠群是否被声明为全长序列 |
productive |
布尔值,指示该重叠群是否被声明为生产性序列 |
fwr1 |
预测的FWR1氨基酸序列 |
fwr1_nt |
预测的FWR1核苷酸序列 |
cdr1 |
预测的CDR1氨基酸序列 |
cdr1_nt |
预测的CDR1核苷酸序列 |
fwr2 |
预测的FWR2氨基酸序列 |
fwr2_nt |
预测的FWR2核苷酸序列 |
cdr2 |
预测的CDR2氨基酸序列 |
cdr2_nt |
预测的CDR2核苷酸序列 |
fwr3 |
预测的FWR3氨基酸序列 |
fwr3_nt |
预测的FWR3核苷酸序列 |
cdr3 |
预测的CDR3氨基酸序列 |
cdr3_nt |
预测的CDR3核苷酸序列 |
fwr4 |
预测的FWR4氨基酸序列 |
fwr4_nt |
预测的FWR4核苷酸序列 |
reads |
比对到该重叠群的reads数量 |
umis |
比对到该重叠群的不同UMI数量 |
raw_clonotype_id |
分配给该细胞条形码的克隆型ID |
raw_consensus_id |
该重叠群被分配到的共识序列ID |
exact_subclonotype_id |
该细胞条形码被分配到的精确亚克隆型ID |
包含所有组装重叠群的核苷酸序列。
all_contig_annotations.csv 的优质子集,仅包含通过质量过滤的高置信度、且来源于细胞的重叠群注释结果。
all_contig_annotations.csv 完全相同。all_contig.fasta 的优质子集,仅包含通过质量过滤和细胞调用的优质重叠群序列。
🎯 核心内容: TCR 和 BCR 克隆型谱系的精确识别、频率统计和 CDR3 序列多样性分析
克隆型统计分析文件,提供每个独特克隆型的详细描述信息。
用途:
内容与格式:
| 字段名 | 详细描述 |
|---|---|
clonotype_id |
分配给该共识序列的克隆型唯一标识符,用于关联和追踪特定克隆群体的所有相关细胞 |
frequency |
观察到的具有该克隆型的细胞绝对数量,反映克隆扩增程度和免疫应答强度 |
proportion |
该克隆型细胞占总细胞群体的相对比例,用于评估克隆优势度和多样性分布 |
cdr3s_aa |
以分号分隔的链:序列对列表,格式为"链名:CDR3氨基酸序列"。链名包括TRA、TRB、TRG、TRD(T细胞受体)和IGK、IGL、IGH(B细胞受体),CDR3氨基酸序列决定抗原结合特异性和功能活性 |
cdr3s_nt |
以分号分隔的链:序列对列表,格式为"链名:CDR3核苷酸序列"。提供CDR3区域的DNA序列信息,用于体细胞突变分析、克隆进化追踪和分子标记设计 |
提供每个克隆型共识序列的详细注释信息。
用途:
内容与格式:
| 字段名 | 描述 |
|---|---|
clonotype_id |
分配给该一致性序列的克隆型ID,对应clonotypes.csv中的克隆型标识符 |
consensus_id |
该一致性序列的唯一标识符,用于关联FASTA文件中的序列 |
sample |
VDJ文库的样本名称 |
length |
一致性序列的核苷酸长度 |
chain |
与该一致性序列相关的链类型:TRA、TRB、IGK、IGL或IGH |
v_gene |
得分最高的V基因片段调用结果 |
d_gene |
得分最高的D基因片段调用结果(如适用) |
j_gene |
得分最高的J基因片段调用结果 |
c_gene |
得分最高的C基因片段调用结果 |
full_length |
布尔值,指示该一致性序列是否被声明为全长序列 |
productive |
布尔值,指示该一致性序列是否被声明为生产性序列 |
cdr3 |
预测的CDR3氨基酸序列 |
cdr3_nt |
预测的CDR3核苷酸序列 |
reads |
支持该一致性序列的reads总数 |
umis |
支持该一致性序列的不同UMI数量 |
包含每个克隆型共识序列的FASTA文件。
consensus_id。🎯 核心内容: V(D)J 组装质量的全面评估和统计指标汇总,提供完整的数据质量控制信息
采用 Excel 格式的关键分析指标汇总表,提供了对实验整体质量的全面评估。
用途:
内容与格式:
包含五大类别的关键指标:
| 指标类别 | 包含内容 |
|---|---|
| 基本统计 | 总读数、有效条形码比例、UMI质量、Q30碱基质量等基础测序指标 |
| 细胞识别 | 估计细胞数量、细胞内读数比例、每细胞平均读数等细胞调用结果 |
| 基因映射 | V(D)J基因映射比例、链特异性映射统计、基因利用度分析 |
| 组装质量 | 全长序列比例、生产性序列比例、CDR3识别成功率等组装效果评估 |
| 克隆型分析 | 克隆型多样性、配对成功率、主要克隆型频率等免疫组库特征 |
内置推荐的质量控制标准,方便用户判断:
采用 HTML 网页格式的交互式综合分析报告。
用途:
内容与格式:
🎯 概述: HTML 网页报告提供了单细胞 V(D)J 测序分析结果的全面可视化展示和详细解读,包含关键性能指标的评估,帮助用户快速了解实验质量和分析结果
HTML网页报告是单细胞VDJ测序分析的综合展示平台,整合了从数据质量控制到下游免疫组库分析的完整结果。该报告采用交互式可视化设计,帮助用户快速评估实验质量、理解分析结果并指导后续研究方向。
💡 使用建议: 建议按照报告展示顺序依次查看各项指标。
⚠️ 质量标准: 各项指标均提供了推荐阈值和质量等级,请结合具体实验目标进行综合评估。
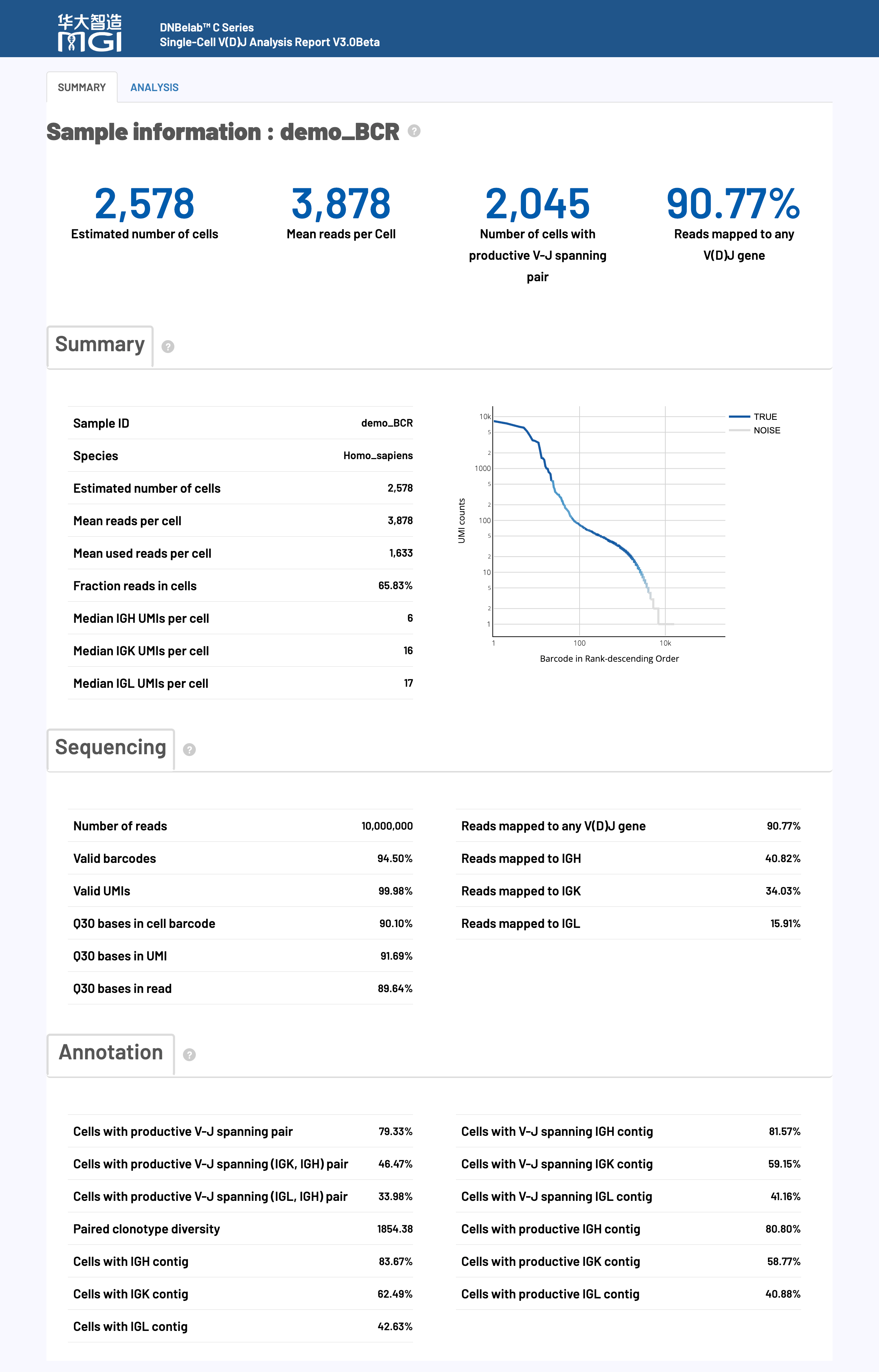
🎯 核心功能: 细胞识别、质量评估和免疫受体组装统计,提供实验整体效果的关键指标
📊 质量控制标准:
注意: 以下标准仅供参考,实际质量评估应考虑组织类型、细胞状态和实验目标等多种因素。不同样本间存在显著差异,建议结合具体实验背景进行判断。
| 指标名称 | 推荐值 | 可接受 | 需优化 |
|---|---|---|---|
| Mean reads per cell | ≥ 10,000 | 5,000–10,000 | < 5,000 |
| Fraction of Reads in Cells | ≥ 50% | 20–50% | < 20% |
🔍 详细指标解释:
| 指标名称 | 详细解释与技术要求 |
|---|---|
|
Estimated number of cells 估计细胞数量 |
|
|
Mean reads per cell 平均每细胞读数统计 |
|
|
Fraction of Reads in Cells 细胞内读数占比 |
|
|
Median TRA/TRB or IGH/IGK/IGL UMIs per cell 每细胞特异性链 UMI 中位数 |
|
|
Number of cells with TRA/TRB or IGH/IGK/IGL contig 含有TRA/TRB或IGH/IGK/IGL重组子的细胞 |
|
|
Cells with V-J spanning TRA/TRB or IGH/IGK/IGL contig 含有V-J跨区TRA/TRB或IGH/IGK/IGL重组子的细胞 |
|
|
Cells with productive TRA/TRB or IGH/IGK/IGL contig 含功能性TRA/TRB或IGH/IGK/IGL重组子的细胞 |
|
|
Paired clonotype diversity 配对克隆型多样性 |
|
🎯 核心功能: 测序数据的基础质量评估,包括条形码识别率、比对质量和测序准确性
📊 质量控制标准:
注意: 以下标准仅供参考,实际质量评估应考虑组织类型、细胞状态和实验目标等多种因素。不同样本间存在显著差异,建议结合具体实验背景进行判断。
| 指标名称 | 推荐值 | 可接受 | 需优化 |
|---|---|---|---|
| Valid barcodes | ≥ 80% | 70–80% | < 70% |
| Valid UMIs | ≥ 80% | 70–80% | < 70% |
| Q30 Base Quality | ≥ 85% | 75–85% | < 75% |
🔍 详细指标解释:
| 指标名称 | 详细解释与技术要求 |
|---|---|
|
Valid barcodes 有效条形码比例 |
|
|
Valid UMIs 有效UMI比例 |
|
|
Q30 bases Quality Q30碱基比例 |
|
🎯 核心功能: V(D)J基因富集效率评估,反映免疫受体序列的捕获效果
📊 质量控制标准:
注意: 以下标准仅供参考,实际质量评估应考虑组织类型、细胞状态和实验目标等多种因素。不同样本间存在显著差异,建议结合具体实验背景进行判断。
| 指标类别 | 推荐值 | 可接受 | 需优化 |
|---|---|---|---|
| Reads mapped to any V(D)J gene | ≥ 50% | 30–50% | < 30% |
🔍 详细指标解释:
| 指标名称 | 详细解释与技术要求 |
|---|---|
|
Reads mapped to any V(D)J gene 泛 V(D)J 基因映射读数比例 |
|
|
Reads mapped to TRA/TRB/IGH/IGK/IGL TRA/TRB/IGH/IGK/IGL 特异性免疫受体链映射比例 |
|
🎯 核心功能: 生产性重排配对分析,评估免疫受体的功能性表达水平
📊 质量控制标准:
注意: 以下标准仅供参考,实际质量评估应考虑组织类型、细胞状态和实验目标等多种因素。不同样本间存在显著差异,建议结合具体实验背景进行判断。
| 指标名称 | 推荐值 | 可接受 | 需优化 |
|---|---|---|---|
| Cells with productive V-J spanning pair | ≥ 40% | 20–40% | < 20% |
🔍 详细指标解释:
| 指标名称 | 详细解释与技术要求 |
|---|---|
|
Number of Cells with Productive V-J Spanning Pair 具有生产性 V-J 跨越配对的细胞绝对数量 |
|
|
Cells with productive V-J spanning pair 生产性 V-J 跨越配对细胞比例 |
|
|
Cells with productive V-J spanning (IGK, IGH) pair IGK/IGH 生产性配对细胞比例 |
|
|
Cells with productive V-J spanning (IGL, IGH) pair IGL/IGH 生产性配对细胞比例 |
|
|
Cells with productive V-J spanning (TRA, TRB) pair TRA/TRB 生产性配对细胞比例 |
|
🎯 核心功能: V(D)J细胞质量控制、UMI分析和免疫受体表达评估的多维度可视化展示
图表功能: 可视化展示每个细胞的 UMI 数量分布(仅统计 productive contig 的 UMI),直观展示细胞质量控制结果和背景噪音水平。
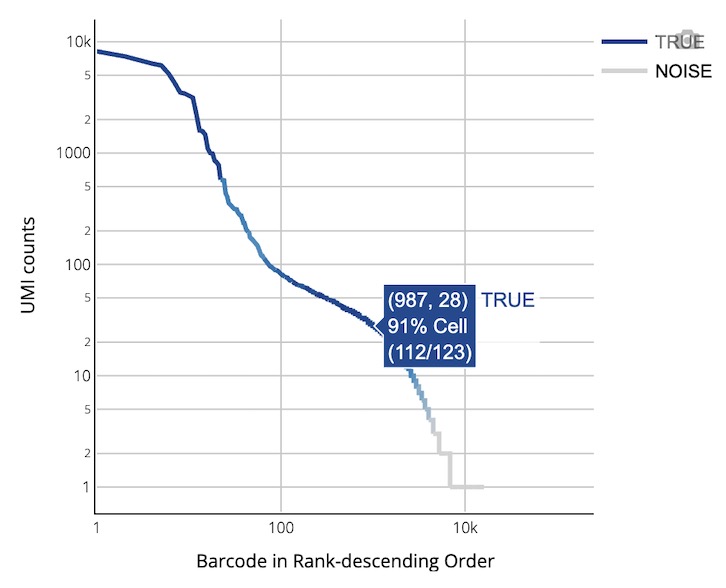
如何解读:
🎯 核心功能: 克隆型丰度分析和免疫受体多样性评估的可视化展示
图表功能: 展示样本中克隆型的相对丰度分布和免疫应答的集中程度。
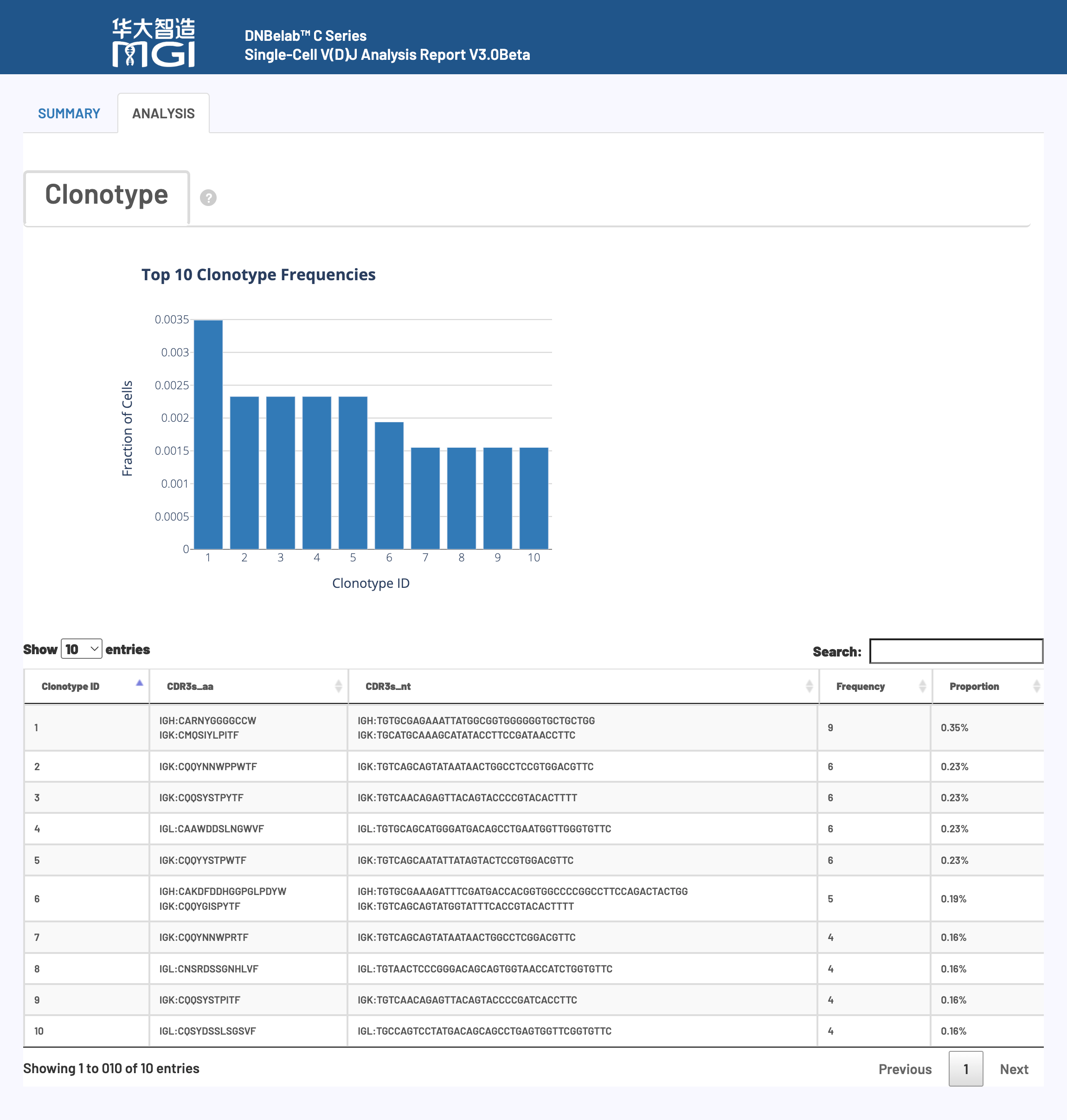
如何解读:
| 文档类型 | 资源链接和描述 |
|---|---|
| 🚀 快速入门 | 快速入门指南 - 第一次分析的完整教程 |
| ⚙️ 参数参考 | 参数参考手册 - 所有可配置参数的详细说明 |
| 🔬 分析流程 | 分析流程说明 - 整个分析流程的技术细节 |
| 🔧 安装配置 | 安装配置指南 - 系统要求、安装步骤和环境配置 |
💡 提示
本文档持续更新中,如发现内容错误或需要补充的信息,欢迎反馈。
📝 文档版本: 3.0 beta | 最后更新: 2025年
🔬 DNBelab C Series HT scVDJ Analysis Software
高性能单细胞V(D)J测序数据分析流程